Regular expression to catch same word twice in a sentence? Thread poster: Hans Lenting
|
|---|
I'm not sure if this is possible at all: a regular expression that catches any word that occurs twice in a sentence (or string), not adjacent.
The difference between ordinary and extraordinary is that little is extra.
| | | |
Rolf Keller
Germany
Local time: 12:22
English to German
| Google for "quantifiers-in-regular-expressions" | Nov 19, 2019 |
Hans Lenting wrote:
I'm not sure if this is possible at all: a regular expression that catches any word that occurs twice in a sentence (or string), not adjacent.
It is a standard feature. See https://docs.microsoft.com/en-us/dotnet/standard/base-types/quantifiers-in-regular-expressions
But this is the .NET dialect for regular expressions. Such quantifiers exist in all dialects, but may use a slightly different spelling.
| | | |
Samuel Murray 
Netherlands
Local time: 12:22
Member (2006)
English to Afrikaans
+ ...
| In which tool/dialect? | Nov 19, 2019 |
Hans Lenting wrote:
A regular expression that catches any word that occurs twice in a sentence (or string), not adjacent.
I'm sure it must be possible, but you're going to have to define a sentence. Regex dialects sometimes have a shortcut for word boundary, but I've never seen sentence boundary pre-defined. Also, tell us what tool you're using (or which dialect of regex).
https://www.regular-expressions.info/backref.html
[Edited at 2019-11-19 10:46 GMT]
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER
Samuel Murray wrote:
I'm sure it must be possible, but you're going to have to define a sentence.
It doesn't necessarily need to be a well-formed sentence: any string would do.
this one matches safety matches
| | |
|
|
|
Dan Lucas
United Kingdom
Local time: 11:22
Member (2014)
Japanese to English
| Match or replace? | Nov 19, 2019 |
Hans Lenting wrote:
I'm not sure if this is possible at all: a regular expression that catches any word that occurs twice in a sentence (or string), not adjacent.
Tricky. Do you want it to be replaced, removed, or are you just trying to find it?
Dan
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | Compare each word with every other word | Nov 19, 2019 |
These are examples where the search expression is being defined. I'm looking for a very general approach, where every word in a multi-word string is compared with every other word in that same string, at a higher character position. Ah, and it should be case-insensitive.
Kind of QA for double words kind.
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER
Dan Lucas wrote: Hans Lenting wrote:
I'm not sure if this is possible at all: a regular expression that catches any word that occurs twice in a sentence (or string), not adjacent. Tricky. Do you want it to be replaced, removed, or are you just trying to find it? Dan
I want to use it to spot segments (strings) where I've used a word twice, inadvertently.
| | | |
| To spot the segment | Nov 19, 2019 |
^.*(\bword\b).*\1.*$
This catches the word "word" which encounters in the segment at least twice.
| | |
|
|
|
Dan Lucas
United Kingdom
Local time: 11:22
Member (2014)
Japanese to English
| Positive lookbehind etc. | Nov 19, 2019 |
Hans Lenting wrote:
I want to use it to spot segments (strings) where I've used a word twice, inadvertently.
This post on StackOverflow was downvoted, but one of its proposed solutions seems to work for me using .Net dialect regexes. (Sorry for use of an image but code was causing problems with the post.)
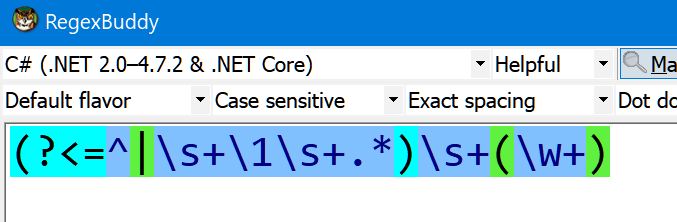
Dan
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | The search word has to be 'hard-coded' | Nov 19, 2019 |
Dan Lucas wrote: Hans Lenting wrote:
I want to use it to spot segments (strings) where I've used a word twice, inadvertently. This post on StackOverflow was downvoted, but one of its proposed solutions seems to work for me using .Net dialect regexes. (Sorry for use of an image but code was causing problems with the post.) Dan
Alas, this only works when you enter the search word:
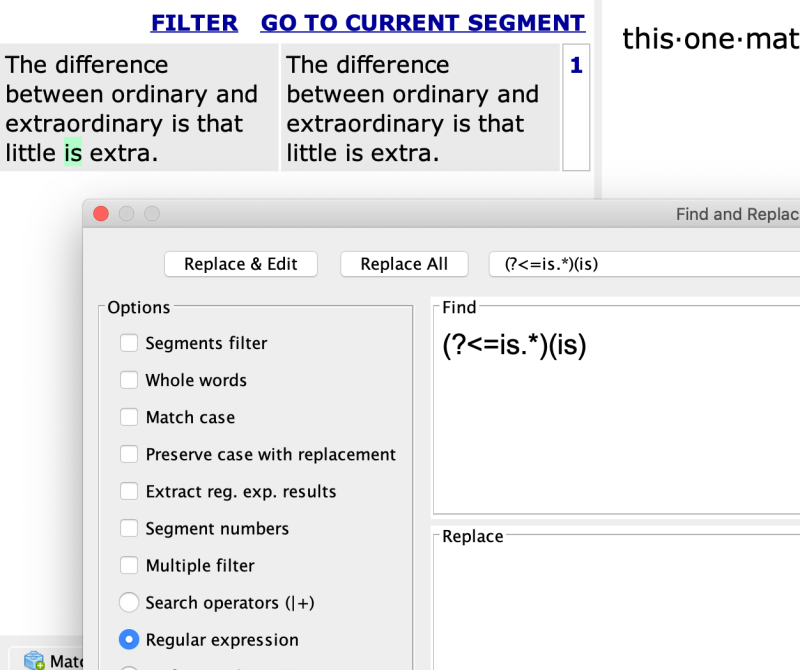
I guess that there are at least 2 steps required:
- Assign every word of the string to an array
- Run the repeated word check on all items of this array
Probably there is some programming needed for this. But perhaps Anthony can solve this puzzle  . .
| | | |
Dan Lucas
United Kingdom
Local time: 11:22
Member (2014)
Japanese to English
Hans Lenting wrote: I guess that there are at least 2 steps required:
- Assign every word of the string to an array
- Run the repeated word check on all items of this array
Probably there is some programming needed for this. But perhaps Anthony can solve this puzzle .
Mmm, if you want to run multiple hardcoded items then PowerGrep could do it by loading a list of terms. See this for example, particularly about the list of literal text in the "Search Types: Single, List or Delimited" section:
https://www.powergrep.com/manual.html#actionterms
PowerGrep isn't cheap, but it's inhumanely competent, and the support is excellent. And you have a three-month guarantee.
Dan
| | | |
Endre Both
Germany
Local time: 12:22
English to German
| What regex flavour? | Nov 19, 2019 |
The following works fine in a number of flavours for simpler cases like your two sample strings.
\b([^ ]+)\b.*\b\1\b
But regex capabilities and syntax vary widely among engines as soon as you go beyond the simple stuff, as Samuel and Rolf pointed out.
| | |
|
|
|
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER
Endre Both wrote:
The following works fine in a number of flavours for simpler cases like your two sample strings.
\b([^ ]+)\b.*\b\1\b
But regex capabilities and syntax vary widely among engines as soon as you go beyond the simple stuff, as Samuel and Rolf pointed out.
Thank you, Endre! Like I said, the flavour is Java: https://docs.oracle.com/javase/7/docs/api/java/util/regex/Pattern.html
@Dan
Thanks for your help too (same goes, without saying for all other repliers too). I'd like to use the regular expression in CafeTran Espresso 10, so an external app is not an option.
And Endre's expression works nicely in CTE:
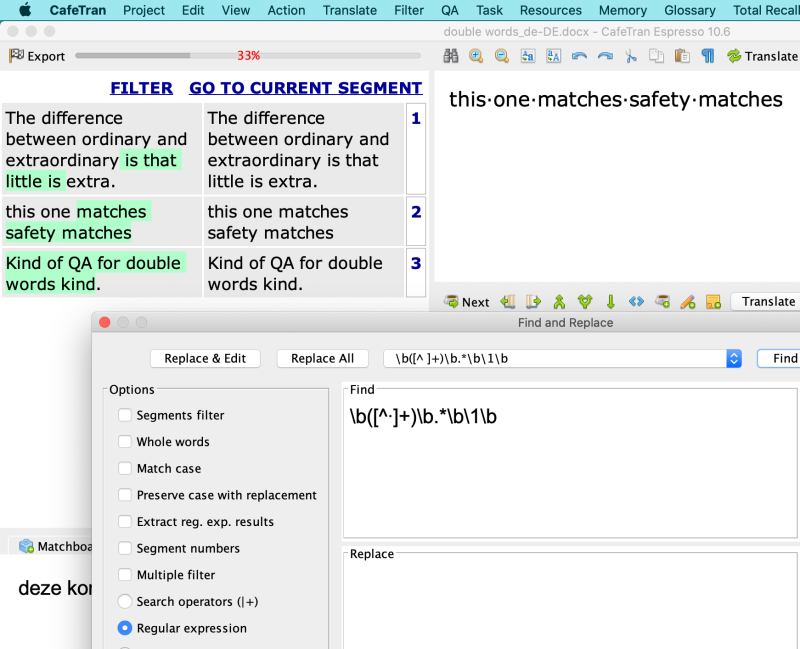
[Edited at 2019-11-19 19:20 GMT]
| | | |
Hans Lenting
Netherlands
Member (2006)
German to Dutch
TOPIC STARTER | Please explain ... | Nov 20, 2019 |
Endre Both wrote:
\b([^ ]+)\b.*\b\1\b
I understand the regular expression, except for the part ([^ ]+). Are you searching for any beginning of a line or space here? And that between word boundaries? Puzzled ...
It sure works, but it'd be nice to also understand it.
Edit: Running the part \b([^ ]+)\b shows that the expression identifies words. Nevertheless, I still don't get it.
[Edited at 2019-11-20 07:27 GMT]
| | | |
Endre Both
Germany
Local time: 12:22
English to German
| Negated character classes | Nov 20, 2019 |
[^ ] is any character except the space. An alternative to \b([^ ]+)\b might be (\w+) – it's the edge cases that might make one or the other preferable.
One caveat with the above is that if a match includes the first of another set of two repeated words, the second set won't be flagged. Using a lookahead to restrict the match to one word rather than the entire text between the two words helps with that:
(\w+)(?=.*\b\1\b)
Jave has an excellent regex engine that pr... See more [^ ] is any character except the space. An alternative to \b([^ ]+)\b might be (\w+) – it's the edge cases that might make one or the other preferable.
One caveat with the above is that if a match includes the first of another set of two repeated words, the second set won't be flagged. Using a lookahead to restrict the match to one word rather than the entire text between the two words helps with that:
(\w+)(?=.*\b\1\b)
Jave has an excellent regex engine that probably allows for many other approaches I haven't thought of. Here's the official Java regex documentation. ▲ Collapse
| | | |








