This site uses cookies.
Some of these cookies are essential to the operation of the site,
while others help to improve your experience by providing insights into how the site is being used.
For more information, please see the ProZ.com privacy policy.
The latest competent intelligence report published by WMR with the title “An Increase in Demand and Opportunities for Global Video Game Translation Services Market 2024” provides a sorted image of the Video Game Translation Services industry by analysis of research and information collected from various sources that have the ability to help the decision-makers in the worldwide market to play a significant role in making a gradual impact on the global economy. The report presents and showcases a dynamic vision of the global scenario in terms of market size, market statistics, and competitive situation.
At present, the Video Game Translation Services market is possessing a presence over the globe. The Research report presents a complete judgment of the market which consists of future trends, growth factors, consumption, production volume, CAGR value, attentive opinions, profit margin, price, and industry-validated market data. This report helps individuals and market competitors to predict future profitability and to make critical decisions for business growth.
The obligatory checkbox on OpenAI’s website, which requires visitors to verify that they are human, seems almost tongue-in-cheek following the company’s latest release, GPT-4o. (The “o” stands for “omni.”)
In a May 13, 2024 announcement, OpenAI described the newest version of its large language model as a “step towards much more natural human-computer interaction,” citing a range of new or improved capabilities, such as human-like response time in conversations and the interpretation of emotions through facial expressions.
“With GPT-4o, we trained a single new model end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network,” the press release explained.
TechCrunch reported that ChatGPT-4o is now “more multilingual,” with OpenAI claiming “enhanced performance in around 50 languages.”
An international conference on the translation of the Quran has been launched in Tripoli, the capital of Libya, Abna news agency reported yesterday.
The three-day event, organized by the Libya Quran Assembly and sponsored by the Islamic World Educational, Scientific and Cultural Organization (ISESCO), focuses on the theme “Precise translation of the Quran’s concepts, a means for promotion of Islam.”
Scholars, researchers, and religious figures from various countries are participating to discuss existing Quran translations, translation challenges, and ways to produce accurate and easily understandable renderings of the holy book in different languages.
Founder Jaroslaw Kutylowski talks about Arabic, the UAE and future clients
DeepL chief executive Jaroslaw ‘Jarek’ Kutylowski wants the company’s translation service to strengthen its presence and usage in the Middle East. Photo: DeepL
DeepL, the AI-fuelled language translation company based in Germany, is keen to strengthen its presence in the Middle East and is making efforts at improving its Arabic translation services while courting potential clients in the region, its chief executive has said.
The company’s AI neural translation technology has set the pace for much of the language-translation sector in recent years, chief executive Jaroslaw “Jarek” Kutylowski, 41, told The National in an interview in Dubai.
The technology translation unicorn’s efforts to increase its presence in the region come amid a global race from various companies like Google, Microsoft and Grammarly, who are vying for a slice of the lucrative language translation sector.
Mr Kutylowski said DeepL offers plenty of VC funding and hundreds of millions of users and is trying to stay ahead of the competition.
Its translation offering for business customers, DeepL Pro, is used by 20,000 companies, according to DeepL.
A Japanese startup said Tuesday it aims to use artificial intelligence to help translate manga comics into English five times faster and 90% cheaper than at present.
Manga series such as “One Piece” and “Dragon Ball” are a huge success story for Japan, with the market projected to be worth $42.2 billion by 2030, according to the startup, Orange.
But it said only about 2% of Japan’s annual output of 700,000 manga volumes are released in English, “partly due to the difficult and lengthy translation process and the limited number of translators.”
But with its technology, Orange aims to produce 500 English-language manga per month, five times more than the industry’s current capacity, and 50,000 volumes in five years. Other languages will come later.
“Compared to translation of a book, translating Japanese used in manga, which uses very short sentences of conversational language often full of slang, is extremely difficult,” said Orange’s marketing vice president Tatsuhiro Sato.
The capability should be generally available in the following weeks.
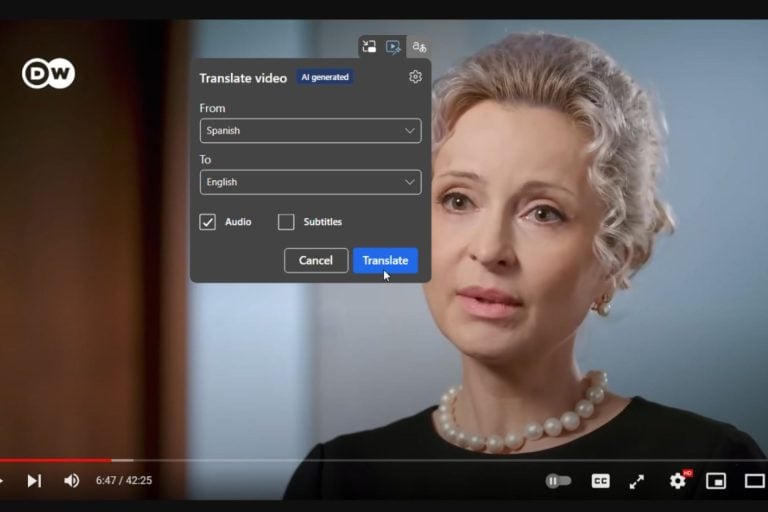
There is no doubt that Microsoft Edge has some good translation capabilities: from the live translation of its PDF reader to the more advanced video translation enhancements that effectively allow users to translate audio or subtitles while watching videos in the browser, Microsoft wants to make sure no one feels left behind.
This is most likely why the Redmond-based tech giant is bringing AI-generated voice dub translations to videos, according to the latest post from software enthusiast @Leopeva64.
In other words, you’ll be able to listen to video translations rather than reading them on Microsoft Edge, all due to a new enhancement that uses AI to generate that audio translation.
“After many attempts and multiple crashes I was finally able to make a short recording of Edge’s video translation feature, in the first video you can hear the original audio and in the second you can hear Edge’s AI-powered translation:https://t.co/FIcnSbSZjTpic.twitter.com/ozilW5YMOc— Leopeva64 (@Leopeva64) May 6, 2024“
According to the enthusiast, Microsoft Edge will have AI generate different voices for dubbing the translation based on who’s speaking. For instance, if a man is speaking in the video, AI will generate a male voice, and if a woman is speaking, then a female voice will be generated.
The Canadian Bureau of Public Services and Procurement (PSPC) is the government agency that oversees the Translation Bureau, which is in turn in charge of supplying linguistic services to Parliament and federal departments. In April 2024, PSPC published a statement announcing the approval and implementation of additional health protection measures for interpreters.
As the use of remote meetings for official government business increased in the 2010s, interpreters began experiencing and reporting issues related to working conditions in these scenarios, all exacerbated during pandemic-related virtual interpreting. At that time, the Translation Bureau provided what it deemed were “firm recommendations” on interpreter protection during virtual Parliament sessions, but no measures were actually implemented until much later.
Classicist Emily Wilson illuminated the intricacies of translation in her lecture “Re-translating Homer: Why and How” held Thursday. The event delved into the challenges and significance of reinterpreting ancient texts for modern audiences.
The lecture was divided into four main topics: defining translation, explaining Wilson’s background and priorities in translation, demonstrating a case study and answering the question of why Homer is still relevant today. Julia Marvin, the chair of the department of the program of liberal studies, introduced the talk.
“The past is a foreign country,” Marvin said. “They do things differently there, and the past is never dead. It’s not even past.”
COLOGNE: Online translation platform DeepL says it launching an AI assistant that, unlike ChatGPT and other rival AI chatbots, is designed to support the writing process with real-time suggestions on word choice, phrasing, style and tone.
The German software company says its new assistant allows users to optimise their texts regardless of their language skills and find the right words for any situation and any reader.
DeepL Write Pro is the company’s first product to be based on its own large AI language model (LLM). LLMs are machine learning models that are trained to understand and generate human language. Well-known LLMs include GPT from OpenAI, Gemini from Google and Llama from the Facebook group Meta.
The new AI writing assistant is primarily aimed at business users and is designed to support teams in companies when writing business content.
DeepL says the assistant, which currently works in English and German, can help companies ensure precise communication from internal content to external customer communications and contracts.
Google has been quiet as Chrome still doesn’t have this functionality. As for Firefox, users will no longer have to use third-party extensions as the Close Duplicate Tabs option is now available in the context menu.
Simply right-click the page that you assume is a duplicate and choose Close Duplicate Tabs from the context menu. This feature is currently available for testing in Firefox 127 Nightly and enabled by default.
While this feature is useful, it only appears if you right-click a duplicated tab, so you’ll need to manually find the tab before closing all of its instances.
German startup DeepL, known for its AI-powered machine translation, is making a foray into the realm of writing where it adjusts the style of the sentences according to user preference with an emphasis on business application.
The startup launched the service, powered by its own large language model (LLM), in Korea on Friday. It is available in English and German with a plan to expand the number of languages supported.
The style of the sentence can be selected from four style options — business, academic, simple and casual — and four tone options — friendly, diplomatic, confident and enthusiastic.
“Words matter, and language can be the competitive edge that moves the needle for global businesses,” said Jarek Kutylowski, the company’s founder and CEO.
“DeepL Write Pro is our first product powered by our own LLMs, and is the culmination of years of research and innovation that has set us apart from other tech giants.”
In early January 2024, when many in the language industry were likely pondering how to eventually incorporate AI into their offerings or processes, OpenAI announced its GPT Store. Back then, a few translation GPTs could be found, including one built by Phrase called “Phrase Expert.”
By the time OpenAI launched the store to the general public, there were already more than three million GPTs done by pre-release testers. After the kind of hype seen in late 2022 with ChatGPT and all the drama surrounding the company’s CEO and Board in 2023, the store launch was also a popular subject in the news and on social media.
Then, the announcement of the company’s text-to-video generator, Sora, arrived in February 2024, lest people get OpenAI out of their minds for too long.
In March 2024, we asked readers if they had ever used Custom GPTs since the store was launched, and over two-thirds of respondents (64.6%) said No. Over a combined quarter of readers said they tested GPTs a bit after launch (14.6%) or from time to time (12.5%), and a very small percentage said they have been using them daily (8.3%).
Anuvadini, the AI translation tool that is breaking boundaries by translating movie dialogues from Vietnamese to diverse Indian languages will also translate ABK Media’s curated, “The Northeast Connect”, digital content into various Indian languages.
ABK Media, under the mentorship of Dr. Triveni Goswami Mathur, an Educator and Media & Communication Expert, has structured content that delves deep into the heart of Northeast India’s richness, a press release said.
The North East Connect digital content aims to promote cultural understanding and inclusivity. By unravelling the region’s socio-cultural complexities and economic potential, this content will serve as a beacon for scholars, entrepreneurs, and policymakers alike.
Overall, it will equip learners with knowledge to contribute positively to Northeast India’s development.
Anuvadini, will also become the first tool to translate the dialogue of a movie into various Indian languages.
Dr Hilary Brown will be leading a project over 2024-25 which will explore what feminist translation means in practice in the twenty-first century.
Dr Brown has been awarded an AHRC Networking grant, together with her co-investigator Dr Olga Castro (University of Warwick/Barcelona), and will be establishing a “Feminist Translation Network” which will bring together researchers, practitioners and educators to discuss feminist approaches to contemporary literary translation in English. The Network will ask questions such as: What is feminist translation (e.g. how does it differ – or not – from translations by women/of women or from queer translation/gender-inclusive translation)? Is feminist translation a matter of identity or a matter of practice? What are the goals of feminist translation and whom is it for?
The Network will address these themes at a series of free public events held over 2024-25, beginning with a translation ‘slam’ and roundtable discussion at the Birmingham Literature Festival in October 2024.
The Network’s activities will be overseen by a steering group which includes former DoML staff member Dr Gaby Saldanha.
In a March 21, 2024 paper, Fan Zhou and Vincent Vandeghinste from KU Leuven demonstrated that language models can predict the most suitable translation techniques for translation and post-editing tasks.
The researchers highlighted a set of persistent issues that remain in MT such as word-for-word translation, false friends, ambiguity, information omission or addition, and cultural insensitivity, leading to low-quality translations that may lack clarity and accuracy. These issues arise from the system using incorrect translation techniques, something a translator wouldn’t do. “The human-generated translation process relies on diverse translation techniques, which proves essential to ensuring both linguistic adequacy and fluency,” they emphasized.
Additionally, they highlighted that “utilizing translation techniques is crucial for addressing translation problems, improving translation quality, and ensuring contextually appropriate translations.”
Zhou and Vandeghinste suggested that automatically identifying translation techniques before can effectively guide and improve the machine translation (MT) process. Additionally, these techniques can serve as prompts for large language models (LLMs) to generate high-quality translations.
We stand on the brink of a new era, fueled by the rapid advancement and integration of Artificial Intelligence (AI). Today, the manufacturing industry is poised to undergo a transformation unlike any it has seen before.
While the transition from manual labor to automated processes marked a significant leap, and the digital revolution of enterprise resource management systems brought about considerable efficiencies, the advent of AI promises to redefine the landscape of manufacturing with even greater impact.
Central to this transformation are Large Language Models (LLMs) and generative AI technologies. These tools are significantly lowering the barrier to entry for subject matter experts and field engineers who traditionally have not been involved in coding or “speaking AI.” The impact of this should not be underestimated. Up to 40% of working hours across industries could be influenced by the adoption of LLMs, a significant shift in workforce dynamics.
AI, and particularly LLMs, will have a profound impact on the manufacturing sector. The opportunities are vast — but there are potential challenges, too.
AI-native language translation application DeepL Translate is launching into Australia and Singapore following regional forays into Japan and South Korea. Founder and CEO Jarek Kutylowski said it is targeting APAC businesses that require more natural language translations.
Tech employees in APAC know working in the region can involve struggles with language. While most cross-border business is conducted in English, there can still be difficulties communicating, which can lead workers to turn to offerings like Google Translate or ChatGPT for help.
Jarek Kutylowski, founder and chief executive officer of DeepL.
The same goes for enterprises looking to win business in the languages of the region. Jarek Kutylowski, founder and chief executive officer of DeepL, said the firm’s natural language processing AI model offers natural language translations in 32 languages, thanks to years of development and fine-tuning since launching in Europe in 2017.
With additional APAC languages on its roadmap for 2024, DeepL is expanding its footprint into Australia and Singapore, with key business use cases including translation for cross-border business growth. Its Pro subscription (starting at US$8.74 per user per month, rising to US$57.49 for an Ultimate package) and API Pro (beginning at $5.49 per month) allow businesses to translate documents at scale or integrate translations within their workflows.
Climate Cardinals is a youth-led nonprofit that’s accomplished quite a bit with almost no funding: translating 2 million words in four years to make scientific literature more accessible to non-English speakers.
Earth Day 2024 marks a turning point for the group, leaders say, with $400,000 in backing from the philanthropic arm of Google.
The nonprofit plans to use the funding to expand its translation capacity from 500,000 words per year to a least 1 million and as many as 3 million words per year, says Hikaru Wakeel Hayakawa, Climate Cardinals’ vice president and deputy executive director.
“This is our anchor funding, though we have several grants from L’Oréal and National Geographic, among others,” says Hayakawa, also a senior at Williams College in Massachusetts.
“We began with a $500 budget and have largely functioned with a near-zero budget with volunteers spending their time on Climate Cardinals between work, sleep and study.”
Translation has consistently been a central focus at London Book Fairs. Translators’ and scouts’ perspectives shape publishing decisions for translations. Nonetheless, their impact on the UK publishing market is limited to 3-6% of the market, which mostly belongs to anglophone writers. Over the last two years, Japanese manga made it clear: the foreign literature segment is poised for growth.
In 2023, the UK witnessed a surge in popularity for manga and cozy novels, with Japanese writers leading the market for translated titles. Seventeen of the top 30 translated authors in Britain hailed from Japan, contributing to nine out of the 20 bestsellers being originally written in Japanese. Kentaro Miura, the manga creator who tragically passed away in 2021 at the age of 54, led the pack of translators. An overwhelming 95% of manga sales came from titles originally published in Japan. Among the top 10 authors in translation who generated over £1 million in sales last year, seven were Japanese, with five of them being manga creators. The only non-Japanese names in the top 10 were Thomas Erikson (3rd) and Andrzej Sapkowski (10th).
The top 20 lists featured familiar names such as Elena Ferrante, Jo Nesbo, Paulo Coelho, and Haruki Murakami. Additionally, new faces emerged in the charts, including Bulgarian author Georgi Gospodinov.
While AI tools have been used by some translators to support their work, three-quarters of those surveyed believe the emerging technology will negatively impact their future income
More than a third of translators have lost work due to generative AI, a survey by the Society of Authors (SoA) has found. More than four in 10 translators said that their income has decreased because of generative AI, while more than three-quarters believe the emerging technology will negatively affect their future income.
The SoA, the UK’s largest trade union for writers, illustrators and translators, ran the survey in January. It found that 37% of translators had used generative AI to support their work, and 8% used it because they were asked by their publisher or commissioning organisation.
Thomas Bunstead, whose translations from Spanish include The Book of All Loves by Agustín Fernández Mallo, said it is important to draw a distinction between literary translators and “commercial” translators. “Though a third of translators have responded to the SoA survey saying they think they’ve lost work to AI already, literary translation remains in the hands of humans,” he said. “The work that has presumably been handed over to AI will be the kind of uncomplicated bread-and-butter stuff which doesn’t require so much nuance,” such as instruction manuals.
The translation news daily digest is my daily 'signal' to stop work and find out what's going on in the world of translation before heading back into the world at large! It provides a great overview that I could never get on my own.
susan rose (X)
United States
You have native languages that can be verified
You can request verification for native languages by completing a simple application that takes only a couple of minutes.
Review native language verification applications submitted by your peers. Reviewing applications can be fun and only takes a few minutes.







{kind=link}